Camoscio GPT: Alternativa a Chat-GPT in Italiano anche su Windows con Ubuntu WSL2


Camoscio è un modello di linguaggio basato su LLaMA, una famiglia di modelli aperti sviluppata da Facebook AI Research, è stato addestrato con una tecnica chiamata low-rank adaptation (LoRA) per rispondere a istruzioni in italiano, usando un dataset tradotto dello Stanford Alpaca instruction-tuning dataset.
Camoscio è disponibile sul hub di Hugging Face e può essere usato per generare testi in italiano seguendo le istruzioni fornite dall'utente con performance in termini di risultato vicino al GPT 3.5 text-davinci-003 .
Camoscio è stato cretato da Andrea Santilli del gruppo di ricerca GLADIA della Sapienza di Roma.
Predisposizione Windows Subsystem Linux 2 con Ubuntu e Nvidia CUDA
Per configurare WSL2 con Ubuntu e CUDA 12.0, è necessario seguire alcuni passaggi preliminari:
- Installare Windows 11 o Windows 10, versione 21H2 o successiva.
- Scaricare e installare il driver NVIDIA CUDA abilitato per WSL dal sito web di NVIDIA. Enable NVIDIA CUDA on WSL 2 | Microsoft Learn
- Abilitare WSL e installare una distribuzione basata su glibc (come Ubuntu o Debian). Windows 11: installiamo una distribuzione UBUNTU con WSL (redhotcyber.com)
- Assicurarsi di avere l'ultima versione del kernel WSL (5.10.43.3 o superiore).
Dopo aver completato questi passaggi, è possibile procedere con l'installazione del toolkit CUDA su Ubuntu seguendo una delle due opzioni:
- Opzione 1: Installazione del toolkit CUDA Linux x86 usando il pacchetto WSL-Ubuntu - Raccomandato. Il pacchetto WSL-Ubuntu contiene solo il toolkit CUDA e non il driver NVIDIA Linux GPU, quindi è sufficiente seguire le istruzioni sulla pagina di download di CUDA per WSL-Ubuntu.
- Opzione 2: Installazione del toolkit CUDA Linux x86 usando il meta pacchetto. Il meta pacchetto contiene sia il toolkit CUDA che il driver NVIDIA Linux GPU, quindi è necessario disinstallare il driver prima di usare questa opzione. Per maggiori dettagli, consultare la guida utente di CUDA su WSL.
Una volta installato il toolkit CUDA, è possibile iniziare a usare le applicazioni esistenti che usano NVIDIA CUDA per l'accelerazione hardware GPU all'interno di un'istanza WSL, come PyTorch e TensorFlow, tramite NVIDIA Docker o installandoli direttamente su WSL.
Eseguire Camoscio GPT su WSL Ubuntu e CUDA 12.0
- Creare un ambiente virtual env dedicato e installare le librerie necessarie
python3 -m venv venv
source venv/bin/activate
pip install -r https://raw.githubusercontent.com/teelinsan/camoscio/main/requirements.txt
- Fix della libreria bitsandbytes per WSL
# get python version
PYTHON_VERSION=$(python --version | cut -c8-11)
# Fix bitsandbytes library
cp venv/lib/python$PYTHON_VERSION/site-packages/bitsandbytes/libbitsandbytes_cuda120.so venv/lib/python$PYTHON_VERSION/site-packages/bitsandbytes/libbitsandbytes_cpu.so
# create python file camoscio.py
touch camoscio.py
- Modificare il file camoscio.py ed inserire il seguente contenuto
# import delle librerie necessarie
import torch
from peft import PeftModel
import transformers
import gradio as gr
from peft import PeftModel
from transformers import LLaMATokenizer, LLaMAForCausalLM, GenerationConfig
# impostazione del runtime su CUDA
assert torch.cuda.is_available(), "Change the runtime type to GPU"
device = "cuda"
# Inizializzo Tokenizer e Model LLAMA
tokenizer = LLaMATokenizer.from_pretrained("decapoda-research/llama-7b-hf")
model = LLaMAForCausalLM.from_pretrained(
"decapoda-research/llama-7b-hf",
load_in_8bit=True,
device_map="auto",
)
# Introduco il modello camoscio
model = PeftModel.from_pretrained(model, "teelinsan/camoscio-7b-llama")
# Routine per la generazione del prompt
def generate_prompt(instruction, input=None):
if input:
return f"""Di seguito è riportata un'istruzione che descrive un task, insieme ad un input che fornisce un contesto più ampio. Scrivete una risposta che completi adeguatamente la richiesta.
### Istruzione:
{instruction}
### Input:
{input}
### Risposta:"""
else:
return f"""Di seguito è riportata un'istruzione che descrive un task. Scrivete una risposta che completi adeguatamente la richiesta.
### Istruzione:
{instruction}
### Risposta:"""
# Configurazione dei parametri di generazione
generation_config = GenerationConfig(
temperature=0.2,
top_p=0.75,
top_k=40,
num_beams=4,
)
# Routine per la valutazione del prompt
def evaluate(instruction, input=None):
prompt = generate_prompt(instruction, input)
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs["input_ids"].cuda()
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=256
)
s = generation_output.sequences[0]
output = tokenizer.decode(s)
return output.split("### Risposta:")[1].strip()
# Rimuovo i warnings
import warnings
warnings.filterwarnings("ignore")
# Inizializzo l'interfaccia gradio
g = gr.Interface(
fn=evaluate,
inputs=[
gr.components.Textbox(
lines=2, label="Instruction", placeholder="Scrivi una breve biografia su Dante Alighieri"
),
gr.components.Textbox(lines=2, label="Input", placeholder="none")
],
outputs=[
gr.inputs.Textbox(
lines=7,
label="Output",
)
],
title="🇮🇹🦙 Camoscio | adrianoamalfi.com guide")
g.launch()
- Lanciare il programma Python e accedere all'interfaccia gradio all'indirizzo http://127.0.0.1:7860
python camoscio.py
Utilizzo di Camoscio GTP
Si può accedere all'interfaccia Camoscio - gradio all'indirizzo http://127.0.0.1:7860.
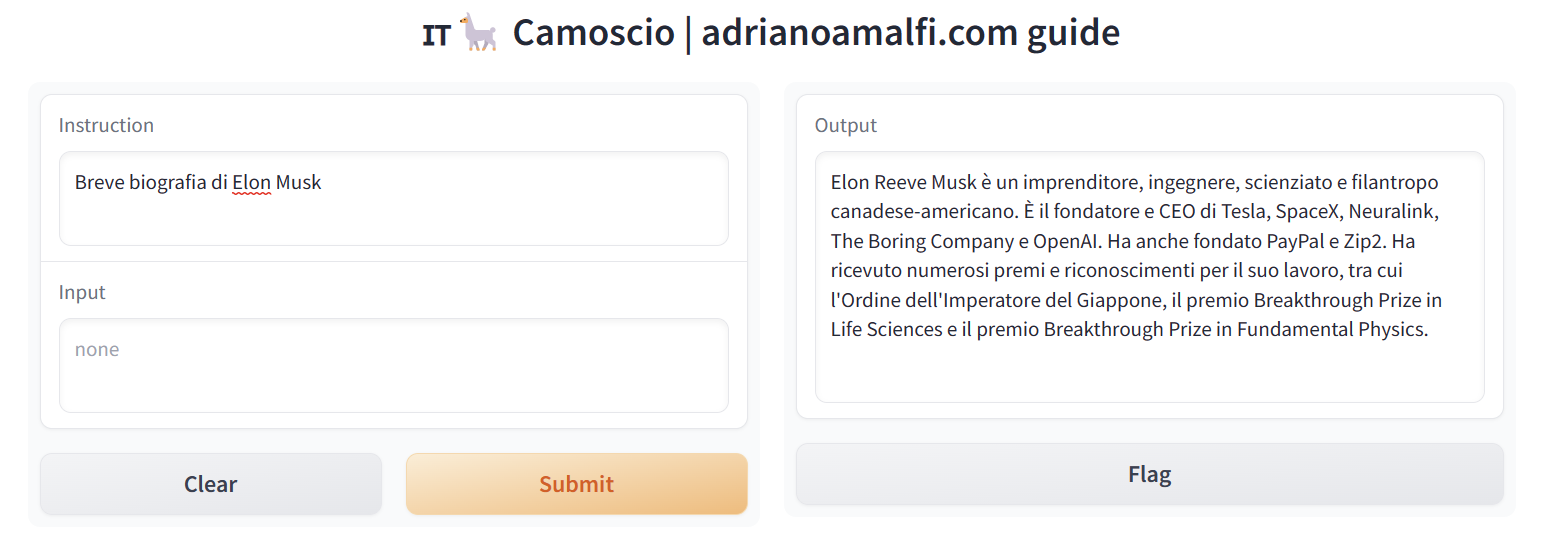
Senza un contesto di input sarà possibile chiedere al modello informazioni come ad esempio una breve Biografia di Elon Musk e la risposta sarà
Elon Reeve Musk è un imprenditore, ingegnere, scienziato e filantropo canadese-americano. È il fondatore e CEO di Tesla, SpaceX, Neuralink, The Boring Company e OpenAI. Ha anche fondato PayPal e Zip2. Ha ricevuto numerosi premi e riconoscimenti per il suo lavoro, tra cui l'Ordine dell'Imperatore del Giappone, il premio Breakthrough Prize in Life Sciences e il premio Breakthrough Prize in Fundamental Physics.
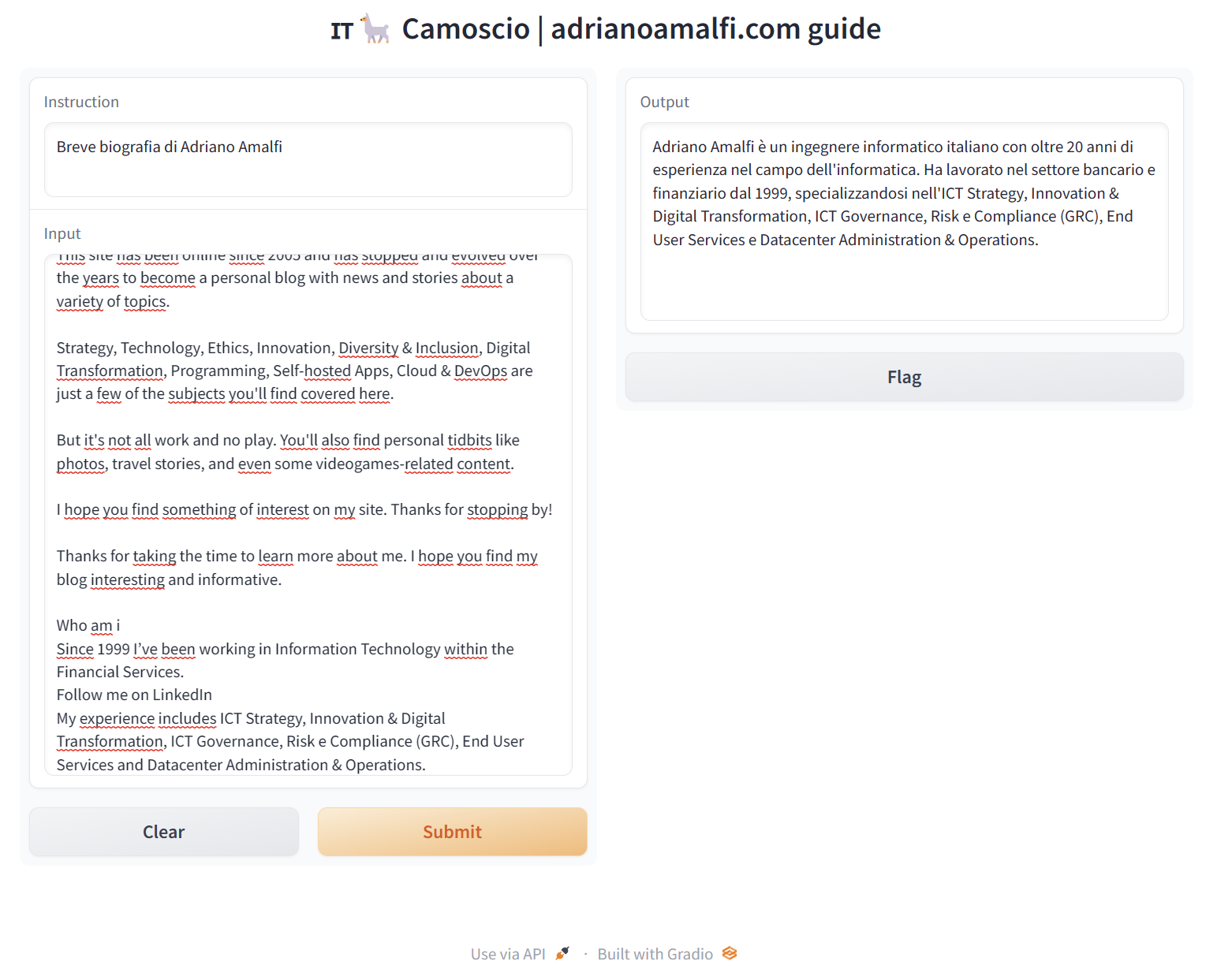
Oppure ad esempio è possibile aggiungere informazioni di contesto nel box Input per dare informazioni al modello. Ad esempio tramite la descrizione della pagina about (in inglese ma ovviamente funziona anche in italiano) gli ho chiesto una breve Biografia di Adriano Amalfi con questo risultato
Adriano Amalfi è un ingegnere informatico italiano con oltre 20 anni di esperienza nel campo dell'informatica. Ha lavorato nel settore bancario e finanziario dal 1999, specializzandosi nell'ICT Strategy, Innovation & Digital Transformation, ICT Governance, Risk e Compliance (GRC), End User Services e Datacenter Administration & Operations.
Extra: Modalità semplice per effettuare il test
Per effettuare un test semplice è possibile ho creato un repository su Github
eseguire i seguenti comandi all'interno della shell
git clone https://github.com/adrianoamalfi/camosciogpt-wsl2.git
cd camosciogpt-wsl2/
chmod +x run.sh
./run.sh
il comando run.sh installa le dipendenze alla prima esecuzione ed esegue il programma python
DIR=venv
if [ -d "$DIR" ];
then
echo "$DIR directory exists."
source venv/bin/activate
python camoscio.py
else
echo "$DIR directory does not exist."
python3 -m venv venv
source venv/bin/activate
pip install -r https://raw.githubusercontent.com/teelinsan/camoscio/main/requirements.txt
# get python version
PYTHON_VERSION=$(python --version | cut -c8-11)
# Fix bitsandbytes library
cp venv/lib/python$PYTHON_VERSION/site-packages/bitsandbytes/libbitsandbytes_cuda120.so venv/lib/python$PYTHON_VERSION/site-packages/bitsandbytes/libbitsandbytes_cpu.so
python camoscio.py
fi
 adrianoamalfi
adrianoamalfiLink utili
 teelinsantatsu-labtloen
teelinsantatsu-labtloen
